Now hiring!
Merkle Trees are the cryptographic backbone of the Web3 ecosystem. From allowing gas-efficient allowlists (airdrops) to enabling lightweight clients (SPV) and powering layer-2 rollups, Merkle Proofs and Merkle Verification are indispensable tools for developers. While typically associated with Solidity and the EVM, the underlying cryptographic principles and vulnerabilities apply across any blockchain architecture, including Rust-based chains like Solana or Move-based chains like Aptos.
However, a misunderstanding of how these trees are constructed can leave smart contracts vulnerable to a specific cryptographic exploit: the Second Preimage Attack. This vulnerability allows an attacker to masquerade an intermediate node of the tree as a valid leaf node, potentially bypassing allowlists or manipulating protocol logic.
In this article, we will deconstruct the mechanics of this attack, visualize the exploit using flow diagrams, and provide the industry-standard mitigations to secure your Merkle Verification logic.
To understand the attack, we must first look at how a Merkle Tree is constructed. A Merkle Tree is a hash-based data structure where every "leaf" node is a hash of a data block (like an address or a transaction), and every non-leaf (intermediate) node is a hash of its children.
In many blockchain implementations, including typical Solidity setups, the standard hashing algorithm is keccak256. A typical construction looks like this:
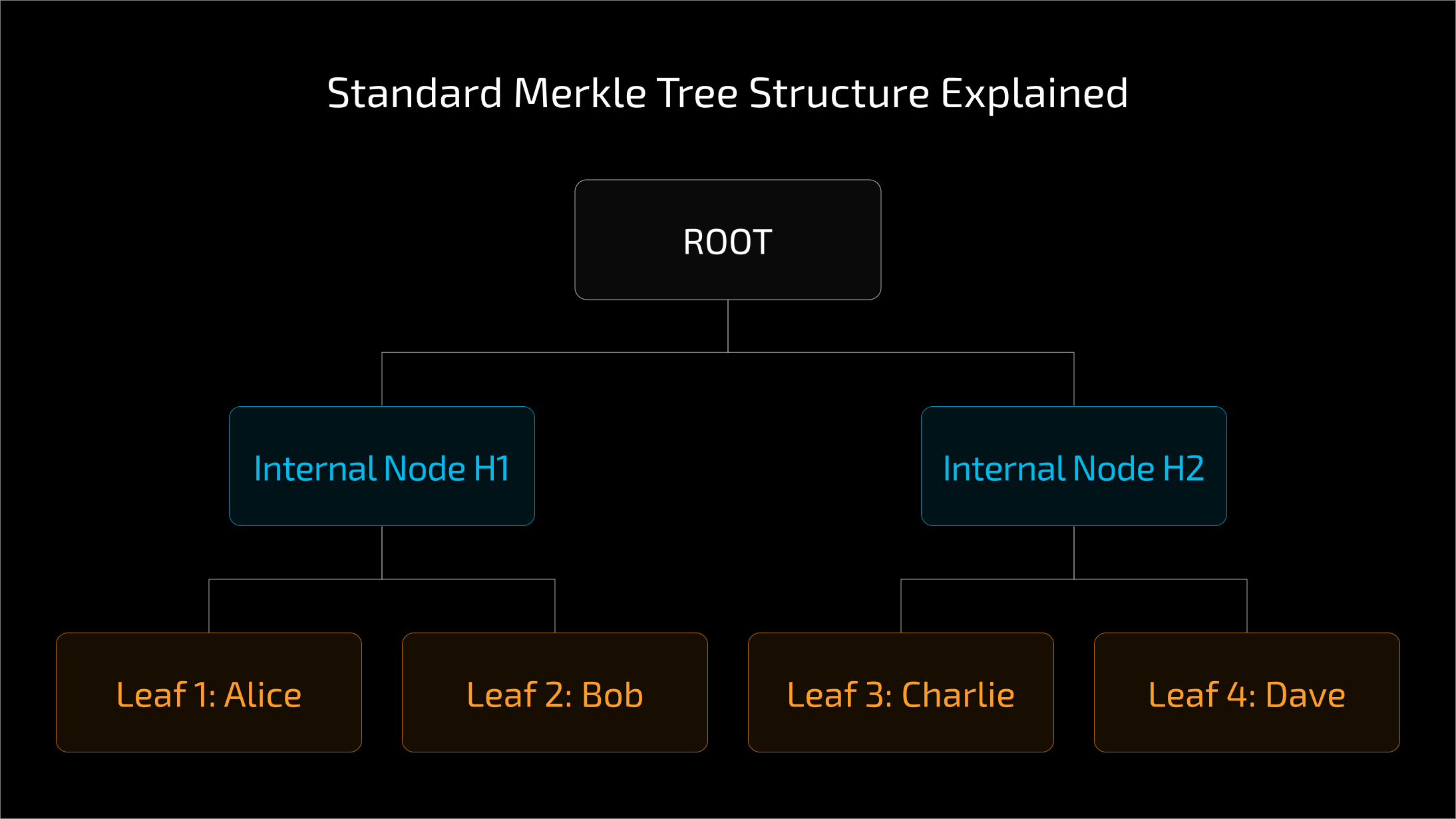
In verification, the smart contract calculates the root by continuously hashing the provided leaf with the proof elements (siblings) all the way up the tree. If the calculated root matches the stored root, the leaf is valid.
The second pre-image attack exploits the ambiguity in how data is concatenated before hashing.
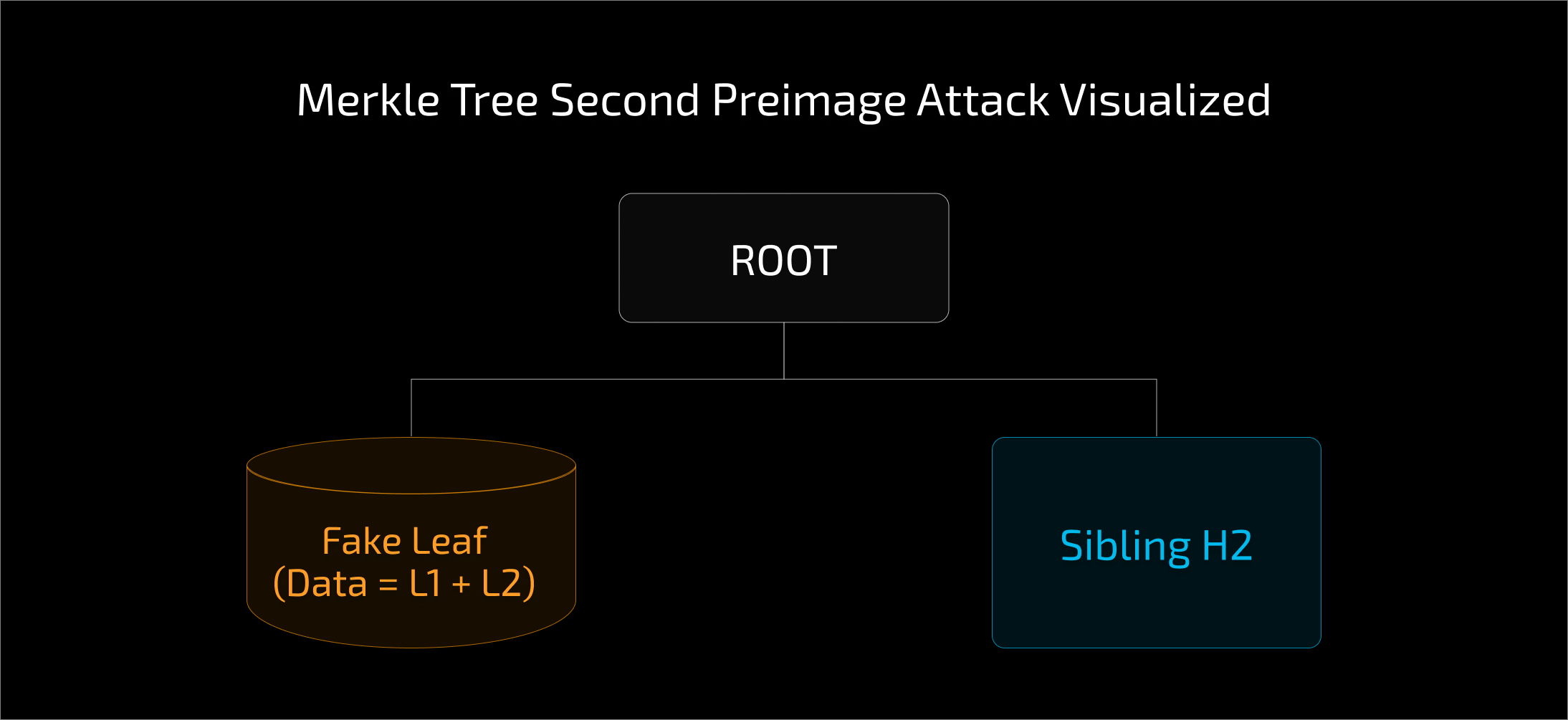
One of the major pitfalls of merkle verification is relying on libraries without understanding their input assumptions.
A common piece of advice is to "always use established libraries." While true, this does not automatically solve the second preimage attack. Libraries like OpenZeppelin handle the mathematics of traversing the tree (hashing $A + B$), but they do not enforce how you generate the leaf $A$ in the first place.
If you pass a 64-byte leaf to a library function, the library will process it blindly.
OpenZeppelin explicitly warns developers about this in their MerkleProof.sol documentation:
"WARNING: You should avoid using leaf values that are 64 bytes long prior to hashing, or use a hash function other than keccak256 for hashing leaves. This is because the concatenation of a sorted pair of internal nodes in the Merkle tree could be reinterpreted as a leaf value. OpenZeppelin's JavaScript library generates Merkle trees that are safe against this attack out of the box.”
To secure your contract against the second preimage attack, you must ensure that the hash of a leaf node can never equal the hash of an intermediate node. This effectively means ensuring the input domain of a leaf hash is distinct from the input domain of an internal node hash.
Here are the two most robust ways to achieve this.
One effective solution is to hash the leaf data twice. This is a form of using a "different hash function" for the leaves.
Because the internal nodes operate on 64-byte inputs and our leaves operate on 32-byte inputs, a collision is mathematically impossible (assuming keccak256 collision resistance holds).
Implementation:
// SECURE: Double hashing ensures the input to the tree is 32 bytes
bytes32 leaf = keccak256(keccak256(abi.encode(msg.sender, amount)));
// Pass this 'leaf' to the MerkleProof library
A more formal cryptographic approach is Domain Separation. This involves adding a distinct prefix byte to data before hashing, differentiating "leaves" from "internal nodes".
This effectively creates two different hashing zones:
0x01 + Data)0x02 + ChildA + ChildB)Due to the different prefixes, even if the data payloads are identical, the resulting hashes will be completely distinct.
The Second Preimage Attack highlights that using audited libraries, such as OpenZeppelin, is necessary but not sufficient. Security lies in the implementation details, specifically, how you construct the data that feeds into those libraries.
Whether you choose double hashing or prefix-based domain separation, the goal remains the same: ensure that a leaf node can never mathematically mimic an internal node.
As Merkle proofs underpin an increasing range of infrastructure, from gas-efficient allowlists and lightweight clients to layer-2 rollups and cross-domain systems, construction mistakes stop being local bugs and become architectural risks. At protocol scale, assumptions about how data is structured matter just as much as the cryptographic primitives themselves.
keccak256(keccak256(...)) or domain prefixes (0x01/0x02) to cryptographically isolate leaves from internal nodes.The Leading Engineers of Blockchain Infrastructure
Nethermind © 2026
.svg)
.svg)

.svg)

.svg)
.svg)



.svg)
.svg)
.svg)
.svg)
















.svg)