Now hiring!
…with early tests showing approximately 20% higher throughput compared to HalfPath
Ethereum state is large, structurally complex, and grows with every block. How a client stores and retrieves that state determines how fast blocks can be processed. Nethermind introduces a new state storage architecture: Flat DB.
Flat DB is a new state storage architecture for the Nethermind Ethereum execution client. It separates account data, storage slot data, and trie nodes into dedicated RocksDB columns, instead of relying on a trie-centric layout for all reads.
It also introduces a layered snapshot and compaction system designed to reduce read overhead during block processing.
The key shift is simple. Instead of always walking a Merkle trie to read state, the client can look up accounts and storage directly from flat key-value columns. The trie is still maintained for root computation and verification, but it is no longer the primary read path.
Flat DB targets the cost of state access during block execution. The EVM interacts with state through SLOAD and SSTORE operations. In trie based storage, these operations require traversing multiple trie nodes from the root to retrieve a value. As state grows, this traversal becomes increasingly expensive.
Nethermind’s prior model, based on HalfPath, stores state in a trie structure. HalfPath significantly improves cache locality over conventional hash based layouts, but it still requires traversing the trie to read state. As state grows, that traversal continues to add cost.
The main inefficiency Flat DB addresses is trie traversal during reads.
Flat DB addresses this by separating accounts, storage, and trie nodes into different columns, and by skipping trie traversal entirely for read-only workloads.

Flat DB also reduces the amount of data read during state access. Trie entries are significantly larger than flat entries, which increases bandwidth and memory overhead during traversal. In testing, trie based reads required substantially more data, sometimes up to tens of times larger than flat entries. Direct flat lookups reduce this overhead and improve read performance.
Flat state storage has been attempted multiple times. Previous implementations often improved read performance but made state calculation slower during commit. In practice, this offset many of the gains.
Nethermind also already includes aggressive caching and speculative execution. The prewarmer handles a large portion of state reads ahead of execution. This means Flat DB must outperform an already highly optimized read path.
Because of this, improving state access alone is not enough. Flat DB must also address commit time, caching behavior, and memory pressure to deliver meaningful performance improvements.
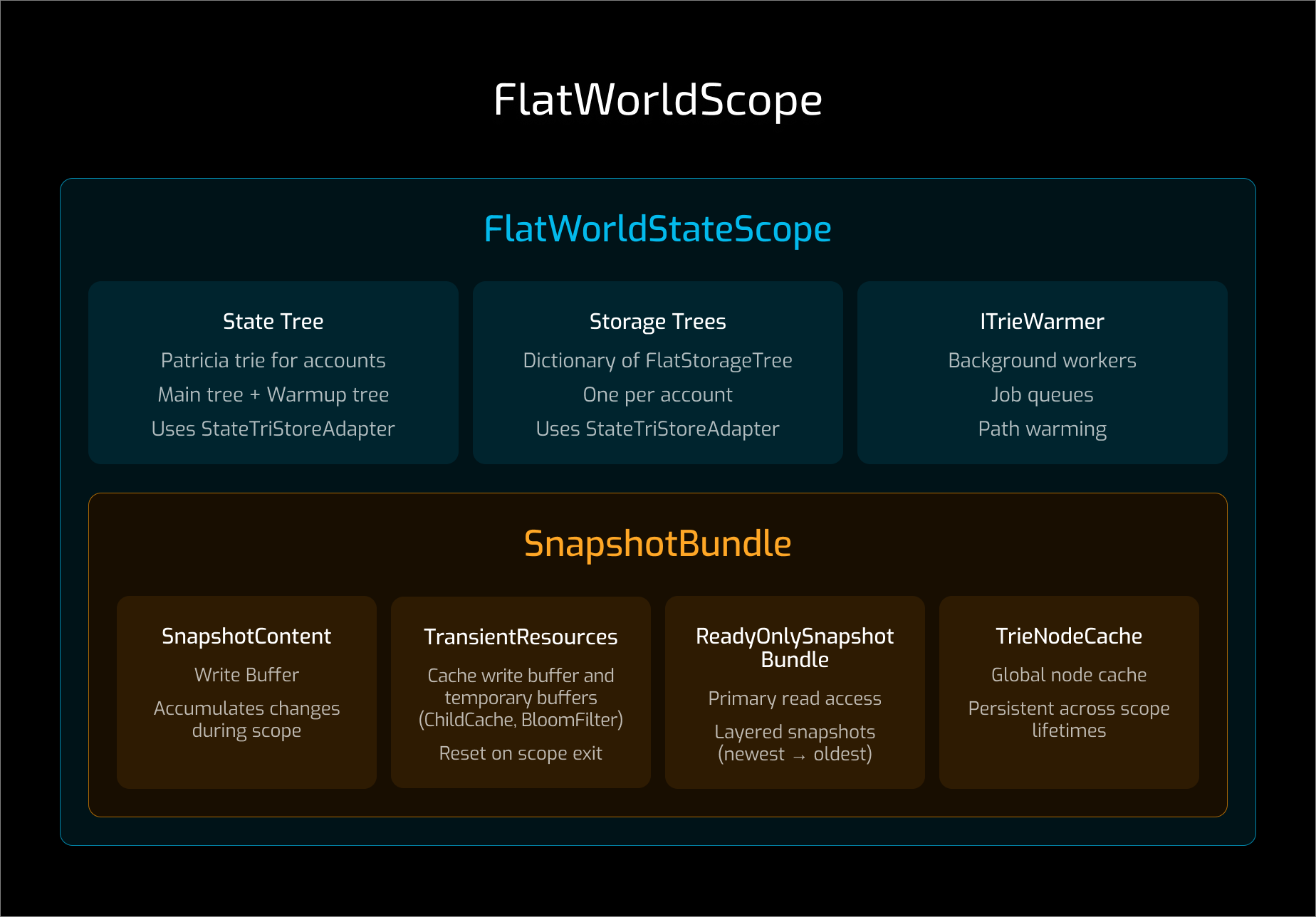
The global state orchestration lives in FlatDbManager which sits on top of an IPersistence abstraction. This allows different database layouts without changing higher level logic. In practice, RocksDB is used.
Flat DB introduces two tiers of snapshots. The first tier contains single block snapshots with recent writes. The second tier contains compacted snapshots that aggregate multiple blocks. The size of these compacted snapshots varies depending on block number. Specifically, the size is the largest power of two that divides the block number, up to a configurable maximum of 32 blocks.
This keeps the number of snapshot layers logarithmic relative to reorg size. Fewer layers need to be traversed during reads, especially when handling deeper reorgs.
The ReadOnlySnapshotBundle, which is the shared read view used by the world state, typically traverses around 7 layers to satisfy the 128 reorg depth required to serve Snap Sync.
However, block processing still needs to calculate the state root. This means trie nodes still need to be fetched, even with flat state access. Optimizing this path is critical for Flat DB performance.
Two components are central to this optimization:
TrieNodeCache, a sharded hash table indexed by path and hashTrieNodeWarmer, which prefetches trie nodes to reduce read latency
Without these optimizations, Flat DB is not significantly faster than HalfPath.
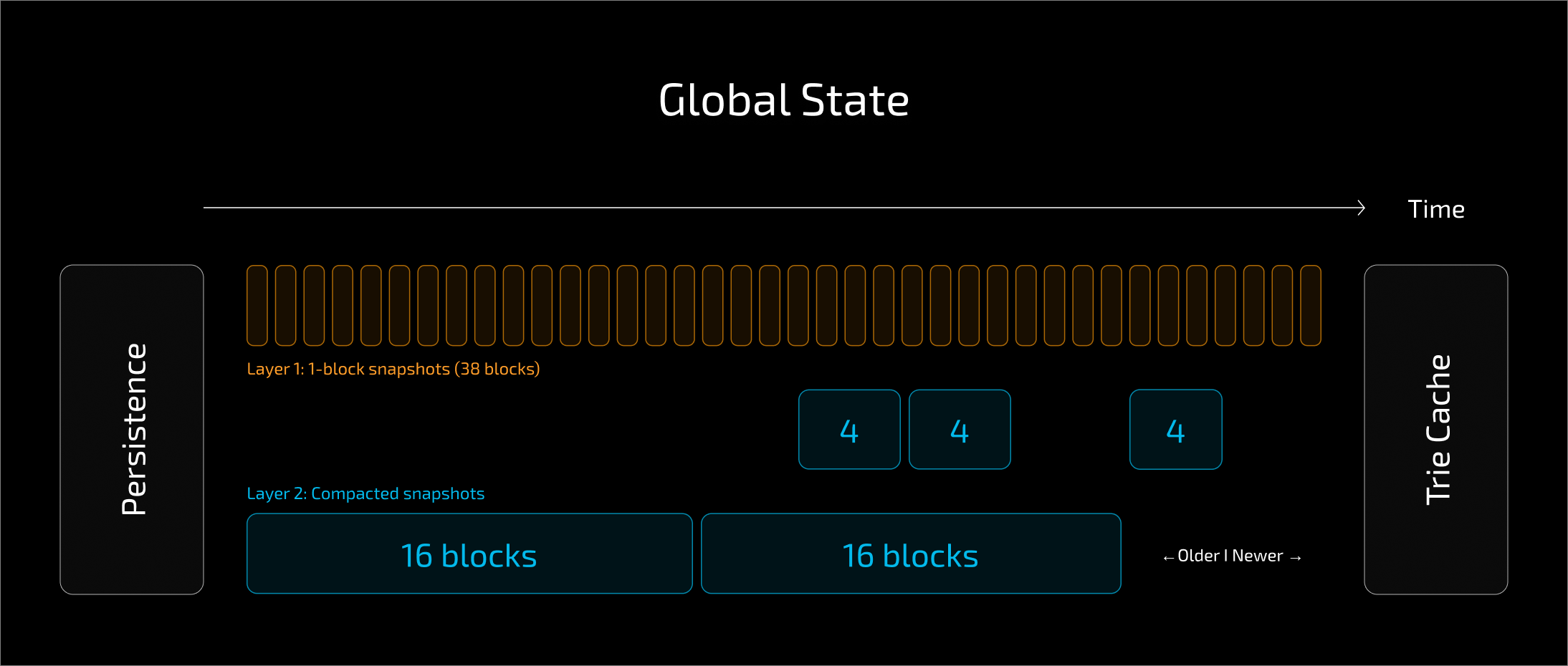
Flat DB relies on snapshot compaction and trie warming to achieve performance improvements. Smaller snapshots are progressively merged into larger compacted snapshots, reducing the number of layers readers must traverse. This helps minimize latency and maintain performance under real workloads, including SnapSync scenarios.
Flat DB is built on a pluggable persistence layer. The IPersistence abstraction allows different database backends and key layouts without changing higher level state logic.
This makes it easier to experiment with alternate storage engines and layouts for different use cases. The design allows experimentation with databases such as RocksDB, LMDB, or Paprika, as well as different key structures optimized for latency, memory usage, or disk efficiency. However, RocksDB remains the most performant solution so far and is the current production backend.
Flat DB currently includes three layouts with different trade offs:
The default Flat layout is designed for the lowest latency while maintaining functional compatibility. The database is tuned for fast reads and minimal access overhead, even at the expense of higher memory usage. The Flat layout also uses 20 bytes of the hashed address for keys. This reduces CPU overhead during comparisons while maintaining low collision risk.
This includes keeping a larger RocksDB index in memory. On mainnet, this is roughly 2.5 GB of RocksDB index data, which is higher than previous configurations. The goal is to reduce lookup latency during block processing.
The layout uses seven RocksDB columns: Metadata, Account, Storage, StateTopNodes, StateNodes, StorageNodes, and FallbackNodes.
Accounts use slim RLP encoding and are not compressed. Storage keys are structured to help RocksDB comparisons. Top level trie nodes are separated into a dedicated column to reduce compaction pressure and improve cache hit rate.
Total database size on mainnet is about 260 GB. This layout is intended for high memory environments, with around 32 GB referenced in testing.
PreimageFlat is identical to the Flat layout, except account and storage keys use raw values instead of hashed keys.
Because keys are not hashed, this layout cannot support sync. It cannot import existing state or use snap sync. As a result, it is primarily intended for experimentation.
In theory, removing key hashing should reduce lookup overhead and improve performance. However, measuring the performance difference is difficult, since the layout cannot currently import or snap sync.
PreimageFlat therefore exists mainly as an experimental configuration to evaluate the impact of key hashing on state access performance.
FlatInTrie is designed for environments where memory is constrained, or where the network state is large enough that the memory overhead of the Flat layout becomes unacceptable.
Instead of maintaining separate flat columns, FlatInTrie embeds account and storage data within trie related columns. This significantly reduces the amount of index data kept in memory. The always resident index size is only a few megabytes.
The smaller database size also improves operating system cache utilization, which can help reduce disk access overhead in memory constrained environments.
The trade off is performance. FlatInTrie is noticeably slower than the default Flat layout, since more lookups rely on compressed storage and partitioned indexes rather than large in memory indexes.
FlatInTrie is therefore intended for lower memory machines or very large networks, where memory efficiency is more important than maximum execution throughput.
In early testing, Flat DB shows around 20% higher execution throughput, measured in MGas per second, compared to HalfPath. Flat DB primarily improves slower state access paths. Nethermind already prewarms a large portion of reads during speculative execution. Flat DB reduces latency when these caches miss. The improvement becomes more noticeable under higher gas limits and storage heavy workloads.
Testing also showed that Flat DB maintains more stable performance under memory pressure. As available memory decreases, trie based layouts degrade more significantly, while flat state access remains more consistent.
In larger stress tests using heavier blocks, improvements of around 40% have also been observed. These gains appear primarily in workloads with high state access, where reduced trie traversal and fewer snapshot layers have the greatest impact.
The improvement comes from reduced trie traversal during reads, lower snapshot traversal depth, and caching of trie nodes.
These results are based on internal testing referenced in the PR discussion. Broader validation across workloads and configurations is still required. Flat DB also reduces raw bandwidth usage during pure state reads, since trie entries are significantly larger than flat entries. However, block processing still requires reading trie nodes to compute the state root. As a result, the overall performance impact can vary depending on workload and the proportion of read versus commit time.
Compacted snapshots can be persisted in the background rather than written block by block, which helps reduce CPU overhead during state persistence
Flat DB is currently alpha and is not enabled by default. The implementation is still under active development, with known issues including occasional hangs and random crashes. It is not yet recommended for production environments.
Flat DB also does not automatically apply to new syncs. Operators must explicitly opt in when testing the feature. Flat DB currently requires explicit configuration when testing. Migration and sync workflows are still evolving.
Snap sync support for Flat DB has already been merged. However, as the implementation remains alpha, operators should still expect instability and ongoing changes.
Key considerations:
Operators interested in testing Flat DB should treat it as experimental and expect further changes as the implementation stabilizes.
Snap sync support for Flat DB has been implemented. However, coordination is more complex, since consistent state must be maintained across reads at the same block height. This behavior is still being validated.
Flat DB introduces snapshot layering and compaction for state data. This changes how state is stored and accessed internally. It does not change block or transaction data.
Flat DB is merged in the current branch but remains alpha and is disabled by default. The implementation is still under active development, with ongoing stability work.
Known limitations:
⚠️ Diagnostic logs such as “unexpected old snapshot” may appear during operation. This behavior is still being investigated.
Flat DB reduces the cost of state access during block processing. As execution becomes more parallel and block sizes increase, state access becomes a larger portion of execution time. Reducing state access latency therefore becomes increasingly important.

Flat DB separates flat state access from trie computation. This creates a cleaner structure for future work and further performance tuning. This includes:
At the same time, some features are not yet available with Flat DB:
Flat DB is a foundational change to how Nethermind stores and accesses state. Early results show higher throughput in the tested setup. Further validation will determine how it performs across different workloads and environments.
The Leading Engineers of Blockchain Infrastructure
Nethermind © 2026
.svg)
.svg)

.svg)

.svg)
.svg)



.svg)
.svg)
.svg)
.svg)
















.svg)