Now hiring!
The first CertiPlonk post, published in November 2025, introduced a framework for extracting and formally verifying constraint systems from Plonky3, with an 8-bit addition circuit as the worked example. The closing line promised a follow-up that would cover how CertiPlonk handles interactions and multi-table proofs, demonstrating the framework's modularity at zkVM (zero-knowledge virtual machine) scale.
Since then, we have applied these techniques to three production-scale Plonky3 codebases: OpenVM, Brevis Pico, and Plonky3's reference Poseidon2 implementation. The way that work landed was different from what the original post anticipated. Rather than centralize a single reusable extractor and bolt each new client onto it, each engagement carried the techniques forward into its own fork of Plonky3 and built up its own Lean reasoning layer over the extracted output. The Lean infrastructure is shared (specifically, the LeanZKCircuit library and the per-bus interface that Section 2 develops), but the Rust-side extraction code lives next to each client's Plonky3 fork rather than upstream of it.
This post is the follow-up promised in November, reframed around the techniques themselves rather than around a single centralized framework. Section 1 covers extraction: how interactions and constraints get pulled out of three different Plonky3 forks (OpenVM, Pico, and Plonky3's own Poseidon2), and the shared methodology that ties them together. Section 2 covers what those interactions become once they reach Lean: an operation language for talking about RISC-V state effects, a generic bus interface, and a translation function that turns a chip's bus row into a list of state effects. The section culminates in a per-opcode equivalence theorem (one chip row, viewed through its bus interactions, behaves exactly like one RISC-V instruction step), and a memory-consistency result that falls out of the bus-balance argument rather than being assumed.
Section 1 covers what happens on the Rust side of each engagement. The job of extraction is to take a Plonky3 AIR (algebraic intermediate representation), evaluate it symbolically, and emit two artifacts per chip: a list of local constraints, and a list of bus interactions. Each row of the chip can contribute multiple tuples to the interaction list, each of the general form (multiplicity, payload_1, payload_2, ...). The multiplicity is positive when the row writes the entry onto the bus and negative when it reads from the bus. For the bus to balance, every payload must carry equal weight of reads and writes, with multiplicities summing to zero.
Once the interactions and constraints are written out, the interaction list becomes the spec-level interface for that chip. Statements about the chip are stated against its interactions, not against its internal column layout. "If the constraints hold, this AIR produces interactions of the form (1, a, b, a+b)" is the shape of a typical spec; the matching consumer-side statement is that a row producing (-1, a, b, c) can assert c = a + b, because the only entries available to balance against on this bus are the producer-side (1, a, b, a+b) entries. The reasoning that converts these row-local statements into chip-wide and system-wide guarantees is the subject of Section 2.
We applied this methodology across three Plonky3 codebases. The summary up front: the extraction code itself is not shared across the three (each lives in its own fork of Plonky3), but the methodology and the downstream Lean format are. Each engagement was a port and an iteration on the last.
OpenVM was the first iteration. The extractor implements the same symbolic AIR builder as the original CertiPlonk post, integrated directly into the version of Plonky3 that OpenVM uses, rather than asking the OpenVM team to move onto our version. The OpenVM model is functionally near-identical to CertiPlonk's, with one structural difference: where the CertiPlonk model uses a single interaction bus, the OpenVM model encodes the bus identity directly into the entry. The two systems are equivalent up to a representation choice. A multi-bus system can be emulated in a single-bus system by prepending a bus index to every tuple, and a single-bus system can be recovered from a multi-bus system by using only one bus index everywhere.
Brevis Pico is the RISC-V zkVM built by Brevis. Our work on it, supported by the Ethereum Foundation, covers instruction-level correctness against the official RISC-V Lean specification, along with execution and memory consistency, and builds on earlier verification work we did on Succinct's SP1 zkVM and on OpenVM (see §1.1). The Pico engagement carried the same extraction approach forward, with most of the changes falling on the side of quality-of-life rather than methodology. The Pico extractor stamps git hashes and timestamps into its output so that downstream Lean projects can confirm they are running against the right revision, and it extracts a full Lean project in one go rather than emitting one constraint file at a time. As with OpenVM, the extractor was ported into the version of Plonky3 that Pico ships, rather than moving Pico onto our fork.
The Lean side uses the standard Plonky3 section of LeanZKCircuit with a single interaction bus. Pico defines several application-level buses (Program, ALU, Byte, State, and Memory), which we model by prepending a unique per-bus index into every payload. Entries on different application buses cannot match against each other because their prepended indices disagree.
One step from the original CertiPlonk pipeline was replaced. The CertiPlonk flow uses deterministic folding lemmas to let Lean simplify chains of constraint expressions. In the Pico extraction, we swapped that step for an AI-assisted simplifier, on the grounds that the deterministic version was not adding enough beyond what a model can produce on the same input. The output remains Lean code that must typecheck and prove its lemmas, so the simplification step itself stays outside the trust base.
The third codebase is the Poseidon2 implementation in the Plonky3 repository itself. Unlike OpenVM and Pico, the Plonky3 Poseidon2 example is upstream of our work, so this is the one case where the original CertiPlonk extractor runs against the unmodified target. The complication was scale. Plonky3's Poseidon2 implementation produces symbolic constraint expressions with billions of nodes each, which is more than the original extractor could write out in any practical time, and more than Lean could plausibly typecheck if we did.
The fix was to cache. Every shared subexpression in the symbolic graph is stored once, and constraint expressions are rebuilt by reference rather than by reduplication. There are edge cases where the same subexpression can arise on multiple distinct evaluation paths and not be detected as identical, and the caching layer is designed to collapse these where possible. The output is roughly 3,000 named subexpressions, each one either a chip column or an arithmetic combination of earlier subexpressions, and each constraint becomes the assertion that one such named subexpression equals zero. Working with 3,000 named atoms is recoverable in Lean. A single billion-node expression is not.
The caching change forced one other change. The auto-simplification step from the CertiPlonk pipeline does not run cleanly over cached graphs, so for Poseidon2 we replaced it with a macro-based reconstruction layer. The Poseidon2 algorithm is highly repetitive and hierarchical (rounds, S-boxes, linear layers), and the subexpressions land in the cache in the order they are created during symbolic evaluation. That gives us a deterministic alignment between blocks of named subexpressions and the higher-level structure of the algorithm. The macros use that alignment to fold the named-subexpression-level constraints back into chunks that match the round and layer structure. With that structure in hand, we proved the chunked Lean Poseidon2 equivalent to an independent reference implementation of the algorithm.
Across OpenVM, Pico, and Poseidon2, the extraction story is the same in shape and different in particulars. The same symbolic AIR builder, ported each time into the target's own Plonky3 fork rather than centralized upstream; the same output format on the Lean side; representation choices on buses that vary by what the application needs; and a caching layer added when the scale of the target demanded it. The interaction list and the constraint list are the artifacts that come out of every run. Section 2 picks them up from there.

A zkVM chip can be thought of as simply a piece of algebra over a finite field, that is, a table of witness columns glued together by polynomial constraints. Conformance to the RISC-V standard, on the other hand, is a claim about a complex state machine, which includes the program counter, 32 registers, a memory map, and an instruction set that mutates them step by step. To state and prove this conformance, we require a translation between the two.
This translation is achieved through the buses. Section 1 hands us, per air, a list of constraints and a list of bus interactions each row contributes to. These bus interactions are the only part of an air's behavior that is naturally read as a state effect. For example: a Program-bus entry says "the row ran the instruction at this PC"; a State-bus entry says "the row read or wrote this value at this register or memory address"; and a Memory-bus entry says "the row performed a load or store of this width, with this extension, at this address". When interpreted as a whole, the bus interactions of one chip row are effectively a transcript of how that row manipulates the RISC-V state.
The remainder of this section formalizes this transcript as a precise Lean object and verifies it. There are three layers that accomplish the work: an operation language for talking about state effects; a generic bus interface for talking about bus contents; and a translation function that turns the second into the first. The benefit is having one clean per-opcode theorem: applying the effects of the buses of a given row of a given chip to a given RISC-V state has precisely the same effect as executing the RISC-V instruction that that row implements on that same RISC-V state.
The first layer is the language we use to talk about effects on the RISC-V state. It consists of seven operations that are sufficient to describe the behavior of all RISC-V instructions. In Lean, and for 64-bit RISC-V, these operations are defined as follows:
-- Supported widths of memory accesses.
inductive MemoryWidth where
| Byte | Half | Word | Double
def width_of_mem_width (mw : MemoryWidth) :=
match mw with
| .Byte => 8
| .Half => 16
| .Word => 32
| .Double => 64
-- Atomic effects on the Sail RISC-V state used by every RV64IM opcode in scope.
inductive Operation where
| ReadPC (val : BitVec 64) : Operation
| WritePC (val : BitVec 64) : Operation
| ReadReg (reg : regidx) (val : BitVec 64) : Operation
| WriteReg (reg : regidx) (val : BitVec 64) : Operation
| ReadMem (addr : ℕ) (mw : MemoryWidth)
(val : BitVec (width_of_mem_width mw)) : Operation
| ReadMemAny (addr : ℕ) (mw : MemoryWidth) : Operation
| WriteMem (addr : ℕ) (mw : MemoryWidth)
(val : BitVec (width_of_mem_width mw)) : Operation
As we can see, we operate with three pieces of state: the program counter, the registers, and memory, through read and write operations, each of which (except ReadMemAny) holds the value being read or written.
In addition, memory accesses come in four widths, matching the four families of load and store opcodes in RV64IM, that is, byte, half-word, word, and double-word. The width is reflected in the type of the value through width_of_mem_width, so that, for example, a ReadMem _ .Half _ operation carries a BitVec 16, and the type system itself enforces that the witness matches the width.
The ReadMemAny variant captures one edge case: a load instruction whose destination is register x0. In RISC-V, writes to x0 are silently discarded, and so it is sufficient to record only that the bytes at the given address are present in memory, without committing to their value.
To compose individual operations into a cumulative effect on a given initial RISC-V state, we need to capture: (i) the post-state of the trace, that is, the state obtained after all writes have been effected, and (ii) the claims that the read operations make about this initial state, such as "register r1 holds this value" or "memory at address addr + 3 holds this byte". The former is what we will eventually compare against the post-state of one RISC-V instruction step; the latter collects the side-conditions under which that comparison is valid. We package both into the following structure:
structure OperationEffect where
hypotheses : Prop
state : EStateM.Result
(Sail.Error exception)
(PreSail.SequentialState
RegisterType
Sail.trivialChoiceSource)
ExecutionResult
To capture the cumulative effect of a sequence of operations on a given starting RISC-V state, we then define a function operation_list_effect that takes a List Operation and a starting RISC-V state, and returns the OperationEffect obtained by applying the operations in order:
def operation_list_effect
(ops : List Operation)
(state : PreSail.SequentialState RegisterType Sail.trivialChoiceSource)
: OperationEffect :=
List.foldl
operation_effect
{ hypotheses := True,
state := EStateM.Result.ok (ExecutionResult.Retire_Success ()) state }
ops
With this language in hand, we can now describe, for each RISC-V opcode in scope, how that opcode affects the RISC-V state. We do this by hand-writing, per opcode, a list of operations that acts as a declarative specification of the opcode. The specs are purely semantic descriptions of the RISC-V opcodes; they make no reference to chips, constraints, or witness layouts, and stand independently as a summary of the RISC-V instruction behavior. We use them as the target against which every chip implementing an opcode is verified, but that is just one of their possible uses. The specs are placed, one per opcode, in PicoFV/RV64IM/RVSail/Opcodes/. The three following examples should make the pattern clear.
The first, spec_ADD, captures the canonical R-type ALU pattern: read the PC and the two source registers, write the incremented PC (the current value plus four), and write the sum to the destination register:
def spec_ADD
(r1 r2 rd : regidx) (pc_val r1_val r2_val : BitVec 64)
: List Operation :=
[ .ReadPC pc_val,
.ReadReg r1 r1_val,
.ReadReg r2 r2_val,
.WritePC (pc_val + 4#64),
.WriteReg rd (r1_val + r2_val) ]
The second, spec_BNE, captures a conditional branch. It reads the PC and the two source registers, and writes a new PC that is either pc + 4, if the two source values are equal (that is, if the branch falls through), or the sign-extended branch offset otherwise. No register is written to:
def spec_BNE
(r1 r2 : regidx) (imm : BitVec 13) (pc_val r1_val r2_val : BitVec 64)
: List Operation :=
let increment := if r1_val == r2_val then 4#64 else BitVec.signExtend 64 imm
[ .ReadPC pc_val,
.ReadReg r1 r1_val,
.ReadReg r2 r2_val,
.WritePC (pc_val + increment) ]
The third, spec_LB, captures both a memory load and the destination-is-x0 edge case from earlier in this subsection. The spec branches on whether the destination register is x0: if it is, the spec emits a ReadMemAny (recording that the byte must exist, without committing to its value) and no register write; otherwise, the spec reads the byte, sign-extends it to 64 bits, and writes it to the destination register:
def spec_LB
(r1 rd : regidx) (imm : BitVec 12) (pc_val r1_val : BitVec 64)
(data0 : BitVec 8)
: List Operation :=
if rd == regidx.Regidx 0#5 then
[ .ReadPC pc_val,
.ReadReg r1 r1_val,
.ReadMemAny (r1_val + BitVec.signExtend 64 imm).toNat .Byte,
.WritePC (pc_val + 4#64) ]
else
[ .ReadPC pc_val,
.ReadReg r1 r1_val,
.ReadMem (r1_val + BitVec.signExtend 64 imm).toNat .Byte data0,
.WritePC (pc_val + 4#64),
.WriteReg rd (BitVec.signExtend 64 data0) ]
To close the loop, we then prove, for each opcode, an equivalence lemma. The purpose of this lemma is to formally connect the hand-written spec to the official RISC-V semantics: provided the read hypotheses hold, applying the operation list produced by the spec to a RISC-V state must yield the same post-state as one step of the corresponding RISC-V instruction. For ADD, the lemma reads as follows:
lemma execute_ADD_equiv
(h : (operation_list_effect (spec_ADD r1 r2 rd pc_val r1_val r2_val) state).hypotheses)
:
execute_instruction (instruction.RTYPE (r2, r1, rd, rop.ADD)) state =
(operation_list_effect (spec_ADD r1 r2 rd pc_val r1_val r2_val) state).state
The same lemma exists for every opcode, with the appropriate substitution. With these lemmas in place, we have, for every RISC-V opcode in scope, a precise description in the operation language proven equivalent to the actual RISC-V semantics.
The other half of the translation consists of making bus contents themselves formal. For this, we need to capture, for every bus: (i) what data each entry carries; (ii) what invariants the entries must satisfy; (iii) the polarity rules under which those invariants are assumed and asserted by chips; and (iv) how an entry serialises to and from its raw field-element form. We package all four into a single generic typeclass, BusEntry, instantiated once per bus and shared identically between the OpenVM and Brevis Pico developments. It lives in Fundamentals/Interaction.lean, and is defined as follows:
class BusEntry (α : Type*) where
multiplicity : α → F
data_length : ℕ
data : α → Vector F data_length
-- Infrastructure-side invariants on every active entry.
axioms : α → Prop
-- Chip-external contract: what the calling chip must guarantee.
externals : α → Prop
-- Bus semantics: the relationship the payload encodes.
wf_properties : α → Prop
-- Polarities of the rely-guarantee, for externals and wf_properties.
wf_assume_cond : α → Prop := fun e => multiplicity e = -1
wf_assert_cond : α → Prop := fun e => multiplicity e = 1
ext_assume_cond : α → Prop := fun e => multiplicity e = 1
ext_assert_cond : α → Prop := fun e => multiplicity e = -1
ext_assume (a : α) := ext_assume_cond a → externals a
ext_assert (a : α) := ext_assert_cond a → externals a
wf_assume (a : α) := wf_assume_cond a → wf_properties a
wf_assert (a : α) := wf_assert_cond a → wf_properties a
-- Serialisation and deserialisation, with proofs of mutual invertibility.
deserialise : F × Vector F data_length → α
inv_ser_deser (x : F × Vector F data_length) : serialise (deserialise x) = x
inv_deser_ser {x : α} : deserialise (serialise x) = x
The first block (multiplicity, data_length, and data) pins down the shape of the data each entry carries, namely how to project the multiplicity and the payload (whose length is known) out of any given entry. The block carries no semantic content; it simply tells the rest of the bus layer where to find the data it needs.
The second block (axioms, externals, and wf_properties) is where the "identity" of the bus lives. Each of these three predicates captures a different invariant, owned by a different actor.
Firstly, axioms represent the infrastructure-side invariant. The Program bus is the canonical example: the transpiler is the unique writer, and for every active entry on the Program bus, the transpiler guarantees that the program counter is 4-byte aligned and within range. No chip is responsible for this; it is, rather, the standing promise of the framework about the bus that can be derived from the original Rust code.
Next, externals are the chip-external contract, that is, what a chip must establish when it interacts with the bus on the call-site polarity. For example, for the ALU bus, externals are statements such as "the opcode is in the supported set" and "the operand limbs are u16-bounded." A chip calls the ALU bus when it needs an arithmetic result; it must satisfy this precondition before it obtains one.
Finally, wf_properties represent the actual semantics of the bus, that is, the relationship that the payload encodes. For the ALU bus, this corresponds to the per-opcode arithmetic equations, a = b + c, a = b XOR c, and so on, one case per opcode. This is what the bus means.
The third block (*_assume_cond, *_assert_cond, and the derived *_assume / *_assert) gives the rely-guarantee polarity rules. By default, wf_assume_cond is "multiplicity = -1" (a read) and wf_assert_cond is "multiplicity = +1" (a write); for externals, the polarities are reversed. Spelled out as four rules:
wf_properties for that entry. The producer justifies the content.wf_properties for free as an assumption. The consumer enjoys the content.externals for free. The producer assumes that the calling convention was honored.externals at the point of consumption. The consumer must satisfy the calling convention.
The overall bus balance is what makes the read polarity sound. Every read on a balanced bus is matched, somewhere in the trace, by a write of the same payload; the proof obligation of the wf_properties of the writer then discharges the hypothesis of the reader. The entire point of routing chip-to-chip communication through buses is, in effect, to factor this matching out of every individual chip proof.
The fourth block (deserialise, inv_ser_deser, and inv_deser_ser) bridges the typed bus-entry world (in which we write specifications) and the raw F × List F world (in which extraction hands us the bus rows). The two inv_* proofs assert that the serialization and deserialization are mutual inverses, which licenses any subsequent reasoning to switch between the two transparently.
The intuition that should stick from this subsection is the single uniform recipe to which every the proof of every chip is reduced: discharge externals on every read, and prove well-formedness on every write. Cross-chip wiring, that is, the pattern "this chip reads what some other chip wrote," is handled, once and for all, by the global bus-balance argument. No chip ever needs to know what is on the other side of the bus.
With the generic interface in hand, we now turn to the concrete buses. Brevis Pico carries five buses (Program, ALU, Byte, State, and Memory), whereas OpenVM carries six (Execution, Memory, Program, Bitwise, RangeChecker, and RangeTupleChecker). The roles are somewhat similar between the two. Here, we focus on the Pico set; all five definitions are placed in PicoFV/RV64IM/RVSail/Buses.lean.
The Program bus is the entry point of the system: it is how every air row learns which RISC-V instruction it is meant to be executing. Each entry on the bus is the transpilation of a single instruction into its field-element-level form, with a 43-field payload that includes the program counter (as three u16 limbs), the opcode (duplicated), three four-limb operands, and 23 opcode-family selectors:
structure ProgramBusEntry where
multiplicity : F
-- 48-bit program counter, encoded as 3 × u16 limbs.
pc_0 pc_1 pc_2 : F
-- Opcode (emitted twice on the bus for historical reasons).
opcode opcode' : F
-- Three operand words, each four u16 limbs.
a_0 a_1 a_2 a_3 : F -- destination (rd or imm)
b_0 b_1 b_2 b_3 : F -- source 1 (rs1)
c_0 c_1 c_2 c_3 : F -- source 2 (rs2 or imm)
-- Indicators.
a_is_0 : F -- destination is x0?
imm_b imm_c : F -- which operand is immediate?
-- 23 opcode-family selectors (is_alu, is_lb, ..., is_jal, is_unimpl).
is_alu is_ecall : F
is_lb is_lbu is_lh is_lhu is_lw is_lwu is_ld : F
is_sb is_sh is_sw is_sd : F
is_beq is_bne is_blt is_bge is_bltu is_bgeu : F
is_jalr is_jal is_auipc is_unimpl : F
The transpiler is the unique writer of this bus. Every air row that runs an instruction reads exactly one Program-bus entry. Its wf_properties predicate states, parametrically, that "there exists a RISC-V instruction such that the transpiler emits this exact payload at this PC and multiplicity." This makes the Program bus, in effect, the formal specification of what a well-formed RISC-V instruction encoding is; the consumer chips therefore never have to re-derive the encoding.
The ALU bus carries the result of every ALU-shaped instruction. The structure of its entry is compact (13 fields, that is, an opcode and three four-u16-limb operands). The most interesting object on this bus is its semantics, ALUBus.Spec, whose purpose is to specify, per ALU opcode, the arithmetic equation relating the result to the operands. It is effectively a large match on the ALU opcode:
def ALUBus.Spec
(ALU_opcode a_0 a_1 a_2 a_3 b_0 b_1 b_2 b_3 c_0 c_1 c_2 c_3 : FKB) :=
let a := U64w.toBV #v[a_0, a_1, a_2, a_3]
let b := U64w.toBV #v[b_0, b_1, b_2, b_3]
let c := U64w.toBV #v[c_0, c_1, c_2, c_3]
let result_range := a_0.val < 65536 ∧ a_1.val < 65536
∧ a_2.val < 65536 ∧ a_3.val < 65536
let operand_range := ALUBus.operandRange b_0 b_1 b_2 b_3 c_0 c_1 c_2 c_3
result_range ∧
match ALU_opcode with
| 0 => a = RV64IM.execute_RTYPE_pure b c .ADD
| 1 => a = RV64IM.execute_RTYPE_pure b c .SUB
| 2 => operand_range ∧ a = RV64IM.execute_RTYPE_pure b c .XOR
| 3 => operand_range ∧ a = RV64IM.execute_RTYPE_pure b c .OR
| 4 => operand_range ∧ a = RV64IM.execute_RTYPE_pure b c .AND
| 5 => a = RV64IM.execute_RTYPE_pure b c .SLL
-- ... opcodes 6..9 ...
| 30 => operand_range ∧ a = RV64IM.execute_MUL_pure b c .MUL
-- ... opcodes 31..37 ...
| 40 => a = RV64IM.execute_RTYPEW_pure (b.setWidth 32) (c.setWidth 32) .ADDW
| 41 => a = RV64IM.execute_RTYPEW_pure (b.setWidth 32) (c.setWidth 32) .SUBW
-- ... opcodes 42..52 ...
| _ => True
The right-hand sides reuse the pure execute_*_pure functions in RV64IM.RVSail.Execution, which are the pure parts of the RISC-V opcode semantics, separated from the monadic machinery of the Lean RISC-V Sail specification. One design subtlety is worth noticing: for opcodes 2/3/4 (XOR/OR/AND) and 30..33 (MUL family), the chip enforces operand u16-bounds internally, and so operand_range lives inside Spec; for the others, the chip does not, and so operand_range ends up in externals instead. This is the rely-guarantee asymmetry of §2.2 playing out concretely.
The Byte bus is a small lookup-table bus for bit-level and range-checking operations. Its structure has only five fields, that is, a byte opcode and four arguments, and its Spec is a flat match over byte opcodes: AND, OR, XOR, byte shifts with carry, less-than, MSB, u8 range, u16 range, and a bit-width range check (x_0 < 2^x_2). We do not prove the byte-bus tables in Lean; we audit them informally and take them as wf_assume on every read.
The State bus is the place where every register and memory access in the system gets recorded, with two refinements that we will rely on later: (i) every entry carries a timestamp (the pair (chunk, clk)), which lets us argue about memory consistency, and (ii) the pointer covers a 48-bit address space, with addresses 0..31 denoting registers and addresses 32.. denoting memory, so that register and memory traffic share one bus. The entry structure is:
structure StateBusEntry where
multiplicity : F
chunk clk : F -- timestamp pair
ptr_0 ptr_1 ptr_2 : F -- 48-bit address as 3 × u16 limbs
x_0 x_1 x_2 x_3 : F -- value as 4 × u16 limbs
The wf_properties of this bus simply state that each value limb is u16-bounded; richer invariants live in externals and in chip-level constraints. The addressing convention is that ptr < 32 denotes a register access, and ptr ≥ 32 denotes a memory access; the State bus is therefore the place where both register and memory traffic live, and it is the bus on which the memory-consistency argument can be made.
The Memory bus carries the higher-level shape of each load or store. We need this in addition to the State bus because the chip-side proof must capture the sign- or zero-extension of a loaded value, and that equation is naturally stated at the mnemonic level (LB versus LBU, for example), not at the byte level the State bus operates on. Each Memory-bus entry carries the mnemonic (LB, LH, LW, LWU, LD on the load side; SB, SH, SW, SD on the store side), the address as the sum b + c of two operand words, the value, and the extension equation linking the read value to its truncated form. The extension equations live in wf_properties, gated on the opcode value and on the a_is_0 = 0 precondition, which captures the rd = x0 case from §2.1:
def MemoryBus.Spec ... :=
-- ... ranges and alignment ...
(opcode = 10 → a_is_0 = 0 → a = BitVec.signExtend 64 (a.truncate 8)) ∧ - LB
(opcode = 11 → a_is_0 = 0 → a = BitVec.signExtend 64 (a.truncate 16)) ∧ - LD
(opcode = 12 → a_is_0 = 0 → a = BitVec.signExtend 64 (a.truncate 32)) ∧ - LW
(opcode = 13 → a_is_0 = 0 → a = BitVec.zeroExtend 64 (a.truncate 8)) ∧ - LBU
(opcode = 14 → a_is_0 = 0 → a = BitVec.zeroExtend 64 (a.truncate 16)) ∧ - LHU
(opcode = 45 → a_is_0 = 0 → a = BitVec.zeroExtend 64 (a.truncate 32)) ∧ - LWU
...
The Memory bus and the State bus sit at different abstraction levels, but they are tied together by a chip-level equivalence theorem, proved in MemoryReadWriteChip.lean. Its shared statement is packaged as the predicate bus_equiv_goal, reproduced below:
def bus_equiv_goal
[Field ExtF]
(air : Valid_MemoryReadWriteChip FKB ExtF)
(row : ℕ)
(state : PreSail.SequentialState RegisterType Sail.trivialChoiceSource)
: Prop :=
let memory_bus : BusRow := {
..., Memory := [ { (bus_row air row).Memory[0]! with multiplicity := -1 } ]
}
let state_bus : BusRow := {
..., State := (bus_row air row).State
}
(operation_list_effect (bus_operations state_bus) state).hypotheses →
(operation_list_effect (bus_operations memory_bus) state).hypotheses ∧
(operation_list_effect (bus_operations memory_bus) state).state =
(operation_list_effect (bus_operations state_bus) state).state
The statement reads as follows. Take the chip's bus row at the row under consideration, and split it in two: on one side, the State-bus entries (the previous- and current-memory accesses at the aligned 8-byte address, both as .Double reads/writes); on the other, the Memory-bus entry (the load or store at the actual address, with width and direction determined by the opcode). The theorem then asserts that, if the State-bus operations succeed when applied to a starting RISC-V state, then the Memory-bus operation also succeeds, and the two emissions produce the same end state. In other words, the two bus-level views of the same memory access agree, both on whether the access is well-defined and on what state it leaves behind. The proof of this equivalence dispatches on the eleven RV64IM memory opcodes, that is, the seven loads (LB, LBU, LH, LHU, LW, LWU, LD) and the four stores (SB, SH, SW, SD), with one lemma per opcode (for example, bus_equiv_LD, bus_equiv_SD, and so on).
The State bus is byte-level and timestamped, because that is the granularity at which memory consistency can be argued. The Memory bus, on the other hand, is mnemonic-level, because that is the granularity at which the extensions of loaded values can be stated. The equivalence theorem above is what guarantees that, despite this difference in abstraction, the two views do not diverge on the underlying access.
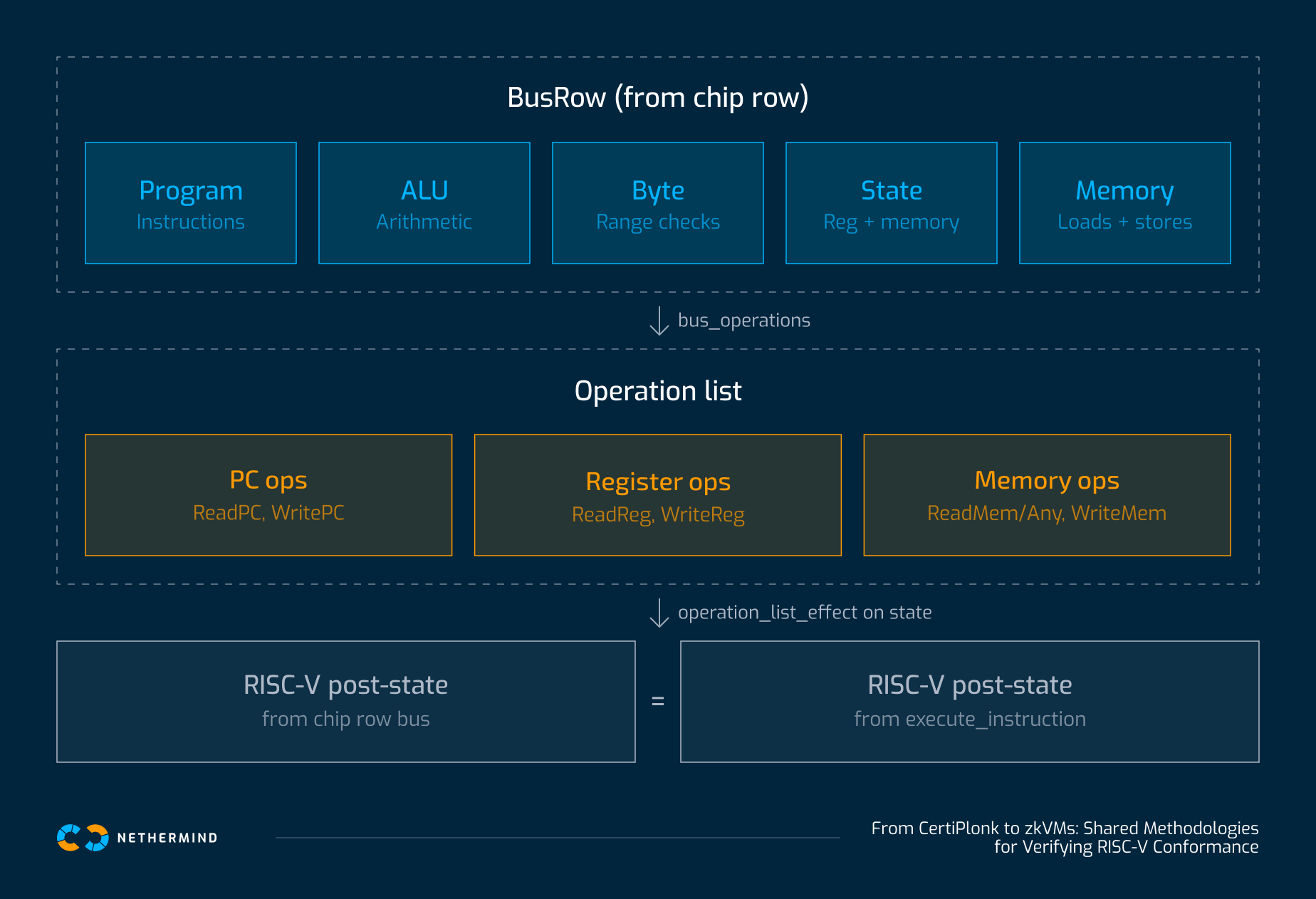
The two halves of Section 2 meet in one function. To translate the behavior of a chip on a single row into the operation language of §2.1, we first need to collect, for that row, all the bus interactions the chip emits. We do this with a single record that bundles one list per bus:
structure BusRow where
Program : List (ProgramBusEntry FKB)
ALU : List (ALUBusEntry FKB)
Byte : List (ByteBusEntry FKB)
State : List (StateBusEntry FKB)
Memory : List (MemoryBusEntry FKB)
With this bundle in hand, we can now define the translation function itself, bus_operations : BusRow → List Operation. Its purpose is to walk a BusRow and produce the list of atomic RISC-V-state operations to which the row corresponds. The dispatch is mechanical, but precise: each Program-bus entry contributes one ReadPC of the PC encoded in its three limbs; each State-bus entry contributes a register or memory operation, depending on whether the address is below or above 32 (that is, on which side of the register-memory boundary baked into the bus's addressing convention the address falls); and each Memory-bus entry contributes a width-appropriate
ReadMem or WriteMem (or a ReadMemAny on rd = x0 loads). To give a flavor, the State-bus dispatch is:
let state : List Operation :=
List.filterMap (fun state_row =>
let value := U64w.toBV #v[state_row.x_0, state_row.x_1,
state_row.x_2, state_row.x_3]
let addr := state_row.ptr_0.val + state_row.ptr_1.val * 65536 +
state_row.ptr_2.val * 4294967296
if _ : addr < 32 then
let register : regidx := .Regidx (BitVec.ofNatLT (w := 5) addr (by omega))
if (state_row.multiplicity = -1)
then .some (.ReadReg register value)
else if (state_row.multiplicity = 1)
then .some (.WriteReg register value)
else .none
else
if (state_row.multiplicity = -1)
then .some (.ReadMem addr .Double value)
else if (state_row.multiplicity = 1)
then .some (.WriteMem addr .Double value)
else .none
) row.State
The Memory-bus dispatch follows the same shape, with the width recovered from the one-hot bus selectors (that is, is_lb, is_lh, is_lw, is_lwu, is_ld, and their store counterparts), and with ReadMemAny taking over on loads where the chip has set a_is_0 = 1. The full definition is around 70 lines, with every dispatch driven syntactically by the bus payload.
With bus_operations defined, we can finally state the per-opcode correctness theorem. The purpose of this theorem is to formally tie a chip row, viewed through its bus interactions, to the RISC-V semantics of one instruction. The theorem has the same shape for every opcode the development verifies; the ADD case, in full, reads as follows:
theorem equivalence_ADD [Field ExtF]
(air : Valid_CpuChip FKB ExtF) (row : ℕ)
(h_row : row ≤ air.last_row)
(h_is_real : air.cols.is_real row 0 = 1)
(h_axioms : ∀ row ≤ air.last_row, bus_row_axioms (bus_row air row))
(h_externals : ∀ row ≤ air.last_row, bus_row_ext_asm (bus_row air row))
(h_wf_asm : ∀ row ≤ air.last_row, bus_row_wf_asm (bus_row air row))
(h_wf_asrt : ∀ row ≤ air.last_row, bus_row_wf_asrt (bus_row air row))
(h_constraints : ∀ row ≤ air.last_row, CpuChip.Extraction.allHold air row)
(h_opcode : air.cols.instruction.opcode row 0 = 0 ∧
air.cols.opcode_selector.imm_c row 0 = 0)
(h_bus_hypotheses :
(operation_list_effect (CPU_bus_operations air row) state).hypotheses)
(risc_v_assumptions : RISC_V_assumptions state mstatus pmaRegion misa mseccfg)
:
let rd : regidx := .Regidx (air.cols.instruction.op_a_0 row 0).val
let rs1 : regidx := .Regidx (air.cols.instruction.op_b_0 row 0).val
let rs2 : regidx := .Regidx (air.cols.instruction.op_c_0 row 0).val
execute_instruction (instruction.RTYPE (rs2, rs1, rd, rop.ADD)) state =
(operation_list_effect (CPU_bus_operations air row) state).state
Reading this from top to bottom: we take a CPU chip air with a real (non-padding) in-range row that runs the ADD opcode (note the immediate flag set to zero); we assume that the chip's bus-row axioms, externals, well-formedness obligations, and extracted constraints hold on every row. Further, we assume that the read hypotheses of the chip's bus row are satisfied, and also that the RISC-V state assumptions, that is, machine mode, single PMA region, no PMP, and so on, hold (the full set of assumptions, with their motivations, is documented in §1.1 of the accompanying report). The conclusion is, then, that executing the RISC-V instruction instruction.RTYPE (rs2, rs1, rd, .ADD) on a given state is exactly the same as applying the operation list extracted from the chip's bus row on that same state. Given previous results, specifically the execute_ADD_equiv lemma (which bridges the RISC-V step to the operation list via spec_ADD) and CPU_bus_operations air row = spec_ADD (extracted args) (which bridges the chip's bus row to the operation list via bus_operations), this gives us the desired equivalence.
This same theorem-shape then repeats for every opcode that the chip implements. We have 62 such theorems for RV64IM and 45 for RV32IM in Pico, collected in the respective Equivalence/Equivalence.lean files. The methodology has, in this way, converged on a single recipe, and the chip-specific work is, effectively, just the arithmetic equation in the middle.
Execution consistency tells us that the opcode execution represented by the chips can be uniquely serialised. Memory consistency tells us that for every address in memory, the reads and writes flowing through it form a single coherent history. In the OpenVM development, these two properties are derived rather than assumed. This is accomplished by relying on: (i) a strictly monotonic measure on the relevant bus entries; and (ii) the global LogUp guarantee that the OpenVM execution bus and memory buses are balanced.
As an aside, a quick word on the two OpenVM buses involved before we go on. The execution bus entries consist of a program counter and a timestamp: (pc, timestamp). Each non-padding row of each chip then emits two such entries, one with negative multiplicity representing the the pre-state, and one with positive multiplicity representing the post-state, with the timestamp of the latter being strictly larger than that of the former, creating a chain of read-write pairs that constitute the execution trace itself. This bus is necessary in OpenVM because OpenVM, unlike Pico, has no dedicated CPU air. Instead, each RISC-V instruction is implemented by its own per-opcode executor chip, and the execution bus is what threads these chips together into one ordered trace. The memory bus carries (as, ptr, x0, x1, x2, x3, timestamp): an address-space tag (denoting, in essence, registers, immediates, or memory), a memory pointer (ptr.val < OpenVM_address_space_size), the four byte limbs of the read or written value, and a timestamp. Memory-bus read-write pairs are chained per pointer, allowing us to state the per-pointer consistency theorem below.
To prove memory consistency, we introduce the WFConstraints typeclass: each chip exposes its execution-bus and memory-bus read-write pairs, together with proofs that the pairs are rising under a joint measure μ and that the memory pairs are same-pointer. A WFChip then wraps a chip together with its WFConstraints instance (with FBB denoting the BabyBear field used by OpenVM):
class WFConstraints (α : Type) (air : α) (μ : List FBB → ℕ) where
execution_bus_entries : List (List FBB × List FBB)
memory_bus_entries : List (List FBB × List FBB)
memory_bus_entries_wf :
∀ a b, (a, b) ∈ memory_bus_entries → (a[1]!.val = b[1]!.val)
rising_pairs_on_execution_bus :
∀ a b, (a, b) ∈ execution_bus_entries → μ a < μ b
rising_pairs_on_memory_bus :
∀ a b, (a, b) ∈ memory_bus_entries → μ a < μ b
The aggregation across chips is then mechanical: execution_bus and memory_bus flatten the per-chip pair lists into bus-wide ones, and execution_bus_is_rising_bus and memory_bus_is_rising_bus promote each chip's local rising obligation to the aggregated bus. For memory we further quotient on the pointer with memory_bus_per_ptr, since the consistency story is one history per address.
The two consistency theorems then read as follows. execution_bus_consistency says: provided the execution bus is balanced by OpenVM's single-balancer convention (a (1, lb) opening lookup and a (-1, rb) closing one), and the total number of lookups fits inside the field characteristic (so that LogUp soundness applies), the bus is a permutation of a strictly increasing chain (lb, x₁), (x₁, x₂), …, (xₙ, rb) with μ(lb) < μ(x₁) < … < μ(xₙ) < μ(rb). The memory analogue memory_bus_consistency_per_ptr says the same for each pointer separately: every individual pointer is either never accessed or its accesses form one such chain.
We've shown how the techniques that started with CertiPlonk scale to two production zkVMs. The shape of the work has converged on a single per-opcode recipe: extract constraints and bus interactions from the AIR, give the buses a precise meaning through a typeclass that captures their payload, externals, and well-formedness predicates, and tie the resulting bus row to one step of the RISC-V state machine through an operation language. The per-opcode equivalence theorem is the unit of work. Each new instruction adds one such theorem, and each new chip is a collection of them. Memory consistency, in the OpenVM development, falls out of the same bus-balance argument that pins the rest of the picture together.
Brevis Pico is still in flight. The development covered here ships with 62 RV64IM and 45 RV32IM per-opcode equivalence theorems and continues to add coverage. Related work in the space includes the Formal Land team's verification of a Plonky3 Keccak-256 implementation via Rocq of Rust (with witness generation modeled), zkSecurity's verification of a Poseidon circuit in their own zkDSL (also with witness generation), and our ongoing CLAP work, which takes the embedded-DSL route to Plonky3-adjacent verification rather than the post-hoc extraction route described here.
The team that built this work is engaging with several zkVM projects right now, with capacity bookable through Q3. zkVM teams weighing the engineering cost of formal verification can find that conversation at nethermind.io/formal-verification.
Substantive technical writing by Petar Maksimović (Section 2, bus modeling in Lean and OpenVM memory consistency) and Dom Henderson (Section 1, extraction across forks).
The Leading Engineers of Blockchain Infrastructure
Nethermind © 2026
.svg)
.svg)

.svg)

.svg)
.svg)



.svg)
.svg)
.svg)
.svg)
















.svg)